
© SEQme s.r.o., 2012 - 2024. Všechna práva vyhrazena.
Právní upozornění.
webdesign Beneš & Michl
Technologie SMRT sekvenování společnosti Pacific Biosciences umožňuje sekvenaci jak fragmentů s délkou v řádu desítek kilobází, tak fragmentů dlouhých pouze několik stovek bází. U dříve používaného systému PacBio RSII se vyskytoval problém s nanášením fragmentů v délce 500 – 1 000 b. Pro fragmenty kratší než cca 500 b byla používána metoda difuze, která ovšem umožňovala maximálně 40% loading, a navíc se u ní projevovala výrazná tendence k efektivnějšímu loadingu kratších fragmentů. Pro fragmenty delší než 1 000 b se dala již efektivně použít metoda nanášení pomocí paramagnetických kuliček. Nanášení fragmentů mezi 500 – 1 000 b bylo však velice problematické. Nejen kvůli tomuto důvodu je sekvenátor RSII v dnešní době již zastaralý, ačkoliv byl na trhu jen krátce, a jeho používání naše společnost nedoporučuje.
Při loadingu SMRT čipů pro systém Sequel, což je technologický následník modelu RSII zmíněného výše, a na kterém aktuálně analyzujeme vaše vzorky, je použit tzv. pre-extension step, který eliminuje zmíněné nedostatky nanášení vzorku difuzí. Díky tomuto kroku lze difuzi využít i pro knihovny s až 15 kb dlouhými fragmenty. Delší knihovny se dále nanášejí pomocí paramagnetických kuliček. Tím je dosaženo situace, kdy pro různě dlouhé knihovny můžeme počítat s podobně úspěšným loadingem a výsledná sekvenační kapacita je pak násobkem počtu readů a délky readů.
Jaké ready však vlastně systém Sequel generuje?
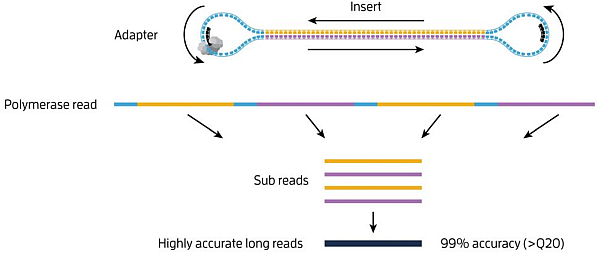
Je zřejmé, že takto vysoké přesnosti čtení nelze dosáhnout u templátů všech délek. Rychlost sekvenace technologií SMRT je 3-4 b/s. Maximální doba sekvenace je 20h. Teoreticky může být tedy dosaženo až ~300 kb polymerázových readů. Kvalita těchto readů ale bude velmi špatná, jelikož polymerázový read bude sám sobě pouze jedním sub-readem.
Celý tento koncept vede ke skutečnosti, že sekvenační výstup v podobě počtu bází velmi závisí na charakteru vstupního materiálu (amplikony vs. gDNA, HMW gDNA vs. degradovaná gDNA) a na následném způsobu zpracování vzorku, kdy můžeme zařadit krok fragmentace a cílit na kratší a kvalitní výsledné sekvence, nebo na delší méně kvalitní.
Příkladem jsou diagramy, které ukazují, že s kratšími fragmenty paradoxně dosáhnete celkově většího sekvenačního výstupu.
|
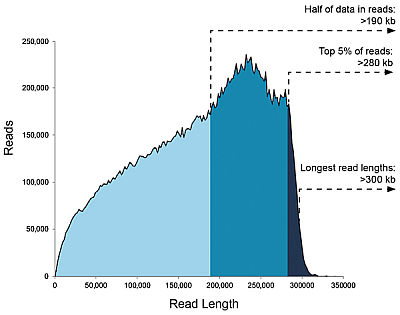
Knihovny <20 kb, data/SMRT čip: Až 50 Gb
|
|
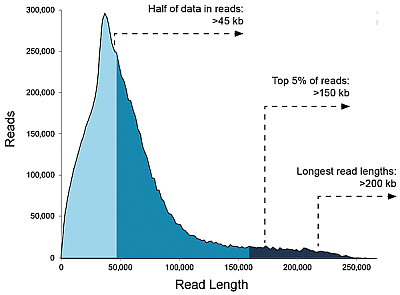
Knihovny>20 kb, data/SMRT čip: Až 20 Gb
|
Možná Vám připadne, že by tomu mělo být naopak, ale je potřeba uvědomit si následující:
Danou situaci ještě lépe vystihuje další diagram:
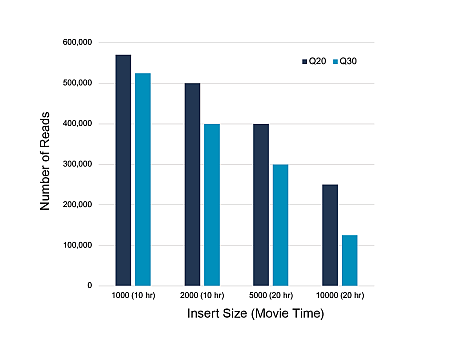
Při plánování sekvenování technologií PacBio prosím vezměte tyto skutečnosti v potaz, případně nás kontaktujte.
Obrázky převzaty z materiálů Pacific Biosciences.
NGS Lab, ngs@seqme.eu