



 Metagenome sequencing
Metagenome sequencing
 Tailed amplicon sequencing
Tailed amplicon sequencing
 RNASeq and differential gene expression analysis
RNASeq and differential gene expression analysis
 Whole exome sequencing
Whole exome sequencing
 Illumina sequencing
Illumina sequencing
 NGS Services à la carte
NGS Services à la carte
 Instruments in our fleet
Instruments in our fleet
© SEQme s.r.o., 2012 - 2024. All rights reserved.
Disclaimer.
webdesign Beneš & Michl

Oxford Nanopore and PacBio sequencing
Long-read sequencing can determine the nucleotide sequence of long sequences of DNA, roughly between tens and hundreds of thousands of base pairs. This removes the need to cut and amplify DNA (which is a standard procedure for short-read sequencing by Illumina).
There are several long-read sequencing technologies commerically available and continuously being developed. Of these, we offer the following two:
| Technology | PacBio | Oxford Nanopore (ONT) |
| Applications | Genome assembly - Analysis of repeats, structural variations - Full-length transcripts, alternative splicing | Genome assembly - Sequencing of longer amplicons eg 16S rRNA gene |
| Project type | Rather larger projects with a higher price. | Rather small to medium projects with a lower total cost. |
| Available sequencing settings | Variable, see our pricelist or contact us | |
| Capacity | Sequel II: approx. 20 Gb HiFi reads Revio: approx. 75 Gb HiFi reads |
MinION: 1-10 Gb |
| Guarantee | The amount of data output is approximate. | |
| Library preparation | We do not allow preparation of libraries by our clients. | |
| Library type | No limits | |
| Outputs | Standard (commonly used data formats etc.) | |
Genome assemblyIn our lab these technologies are primarily requested by customers interested in assembling new genomes (but not necessarily). Genome assembly is the computational process of deciphering the sequence composition of DNA within the cell of an organism, using short or long (or both) sequencing reads. It can be described as solving a jigsaw puzzle. The DNA fragments (pieces) produced by long-read sequencing are easier to assemble into a complete DNA sequence simply because they are longer, same as jigsaw puzzle with less larger pieces. This makes the long-read sequencing the technology of choice for this task. However, due to lower data quality of long-read technologies overall it is beneficial to think of combining them with Illumina short reads. Read about genome assembly by using data from Oxford Nanopore and Illumina technologies! |
|
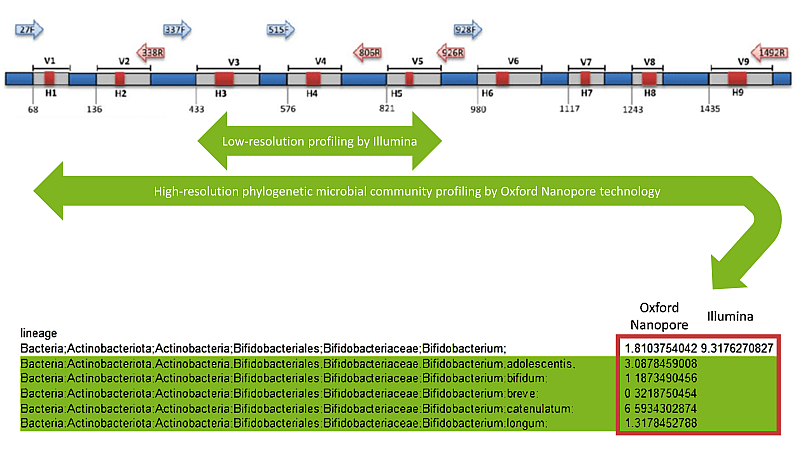
Full-length 16S sequencingWhen identifying some bacterial species, eg in complex communities, Illumina amplicon sequencing is insufficient and the entire 16S rRNA gene needs to be sequenced. ONT technology is particularly suitable for this approach. Technologically, it is similar to any amplicon sequencing. Special primers compatible with downstream sequencing are used and samples can be multiplexed into one sequencing library. We will arrange the entire process for you on a turnkey basis, including long-range PCR on the gDNA supplied by you.
|
|
For PacBio/ONT technologies, we do not allow preparation of libraries by our clients. You must supply DNA/RNA.
Once the sequencing run is finished, you will receive its standard outputs from us. Because each sequencing project has specific data analysis requirements, we offer turnkey data analysis for the needs of your project - Custom Data Analysis. Our bioinformaticians can help you with any data analysis goal. If you are interested in this service, individual consultation is required, we recommend you seek our help already at the project preparation stage.
If you are new to NGS, we encourage you to attend our two-day NGS introductory course. We will be happy to welcome you on some of other courses and workshops too.
If you want to order these services, please contact us to get a price quotation.