
© SEQme s.r.o., 2012 - 2024. Všechna práva vyhrazena.
Právní upozornění.
webdesign Beneš & Michl
Podobně jako asi málokdo vyrazí do divadla či na sportovní zápas, aniž by věděl, co je na programu nebo kdo proti komu hraje, i v případě objednání různorodých služeb je normální mít předem alespoň trochu představu, co od poskytovatele dané služby mohu čekat. Od konkrétních požadavků se přirozeně odvíjí to, jak KVALITNĚ, RYCHLE a ZA JAKOU CENU danou službu mohu získat, což samozřejmě platí i v oblasti DNA sekvenování. Je pochopitelné, že většina klientů by byla ráda, aby byla všechna tato tři kritéria splněna současně na 100 %, ale naprosto otevřeně říkáme, že to není v podstatě možné. Pokud vám někdo tvrdí, že zvládne sekvenovat za nejnižší cenu na trhu v nejkratším možném termínu a současně dosáhne špičkové kvality, není k vám upřímný. Tato skutečnost je trefně zobrazena (obecně známým) diagramem:
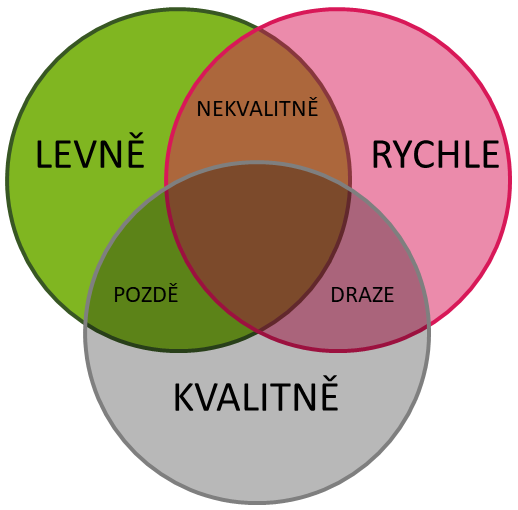
Poskytovatelé sekvenačních služeb sázejí na různé přístupy, častěji však inklinují k variantě „levně a rychle“. Troufáme si však tvrdit, že u sekvenačních analýz rozhodně vždy neplatí, že čím rychlejší, tím lepší! Důvod je jednoduchý – sekvenační nástroje (sofistikované analyzátory, softwarové vybavení, atd.) jsou sice velkými pomocníky, ale pro dosažení nejvyšších kvalit sekvenační analýzy jsou zapotřebí další práce, které mohou provádět pouze kvalifikovaní lidé a které vyžadují určitý čas. Mluvíme zejména o několikeré kontrole (přijímaných vzorků, workflow, výsledných dat apod.), operativních řešeních případných problémů, společné komunikaci a konzultaci se zákazníkem, event. zohlednění zvláštních požadavků na sekvenační analýzy (laboratorní i datové). Ze zkušenosti víme, že jedině tímto přístupem lze dodat vysoce kvalitní výsledky, a přitom zákazníkům nakonec mnohdy ušetřit čas i peníze, a je pro nás velkou výzvou se tomuto ideálu co nejvíce přiblížit.
Různé přístupy k analýze a kontrole sekvenačních dat
V rámci Sangerova sekvenování může být příkladem rozdílných přístupů k dodání služby především oblast hodnocení a úprava vašich sekvenačních dat.
Sekvenační data (elektroferogramy a sekvence) mohou být výsledkem získaným buď výhradně pomocí automatické analýzy (bez kontroly lidského oka či zásahu lidské ruky) nebo včetně této kontroly / zásahu provedeného zkušeným operátorem (SEQme přístup).
K vysvětlení této problematiky musíme trochu zabrousit do technických detailů procesu. Zjednodušeně řečeno, automatická analýza sekvenačních vzorků se provádí pomocí programu Data Collection genetických analyzátorů a následně typicky (nikoliv výhradně) softwaru Sequencing Analysis, jehož součástí jsou tzv. basecallery (algoritmy) pro analýzu vzorků. Tento proces zahrnuje veškerá nastavení nezbytná pro analýzu hrubých dat a vygenerování (odečet) sekvence, např. nastavení počátečního a konečného bodu analýzy, spacingu (vzdálenost píků), nastavení pro detekci směsných bází atd. Obecně lze říci, že při správném nastavení poskytuje automatická analýza většiny vzorků dobré výsledky. Avšak, ve spektru možných variant sekvenačních dat existují poměrně četné případy, kdy lze manuální úpravou a reanalýzou (včetně využití placených softwarových nástrojů) dosáhnout výsledků podstatně vyšší kvality, než poskytne analýza automatická!
Hodnocení kvality vašich sekvencí a jejich úpravu tedy v SEQme vždy nejprve provádí stroje a automatický software, ale následně takto vyhodnocená data vždy a bez výjimky posuzují i lidé. Manuální (lidmi prováděná) analýza sekvenačních dat pochopitelně vyžaduje know-how, zkušenosti a čas, ale protože věříme, že při poskytování sekvenační služby jde v prvé řadě o kvalitu, věrohodnost a maximální využitelnost výsledných dat a teprve pak o rychlost dodání, jdeme od počátku poskytování našich služeb touto cestou.
AKTUALIZACE: Od října 2022 zařadíme do naší nabídky protokol RapidSeq, který představuje vybočení z filozofie, popsané výše. Vyhodnocení výsledků získaných protokolem RapidSeq probíhá bez zásahu lidské ruky! Každý výsledek je ihned po dokončení v sekvenátoru algoritmicky zpracován a automaticky odesílán klientům. Zařazením tohoto protokolu se snažíme vyjít vstříc klientům, pro které je doba dodání výsledků zcela kritický parametr!
Co se tedy rozumí pod oním pojmem manuální/vizuální hodnocení sekvenačních dat, co tím získáváme a v jakých případech?
Níže je několik příkladů, z kterých je přínos jasně zřejmý. Všechny obrázky vždy nejprve ukazují výsledek automatické analýzy a následně výsledek získaný z téhož vzorku po zásahu operátora!
• PeakTrace – spolehlivá data nad 850 bp?
PeakTrace je placený sekvenační basecaller, který přepočítává vaše .ab1 soubory pomocí vlastní série algoritmů, což v jistých případech efektivně zlepšuje zobrazení jednotlivých bází a prodlužuje délku sekvenačního čtení. Známe tento nástroj a jeho nastavení velmi dobře a na základě našich zkušeností umíme rozhodnout, kdy je jeho použití přínosné, protože to rozhodně není vždy. Pokud máme za to, že to smysl má, analýzu PeakTrace zdarma poskytujeme.
Vzhledem k tomu, že kapilární elektroforéza automatických DNA sekvenátorů je optimalizována pro čtení fragmentů dlouhých přibližně 850 bp, spolehlivost a použitelnost sekvenačních dat se za touto oblastí postupně zhoršuje (široký tvar píků, jejich překryvy a především nízké skóre kvality). Zatímco automatický basecaller je v těchto případech nepřesný až chybový, PeakTrace dosahuje vysoce kvalitního čtení až do přibližně 1200bp. Jeho využití se tedy dá uplatnit zejména u delších PCR fragmentů či plazmidů. PeakTrace také při vhodném nastavení dokáže přesněji identifikovat a kvantifikovat polymorfní místa v sekvenci, respektive odstranit nežádoucí data (sekvenační elektroforetické artefakty, pozadí způsobené minoritní přítomností vedlejších produktů v reakci apod.).
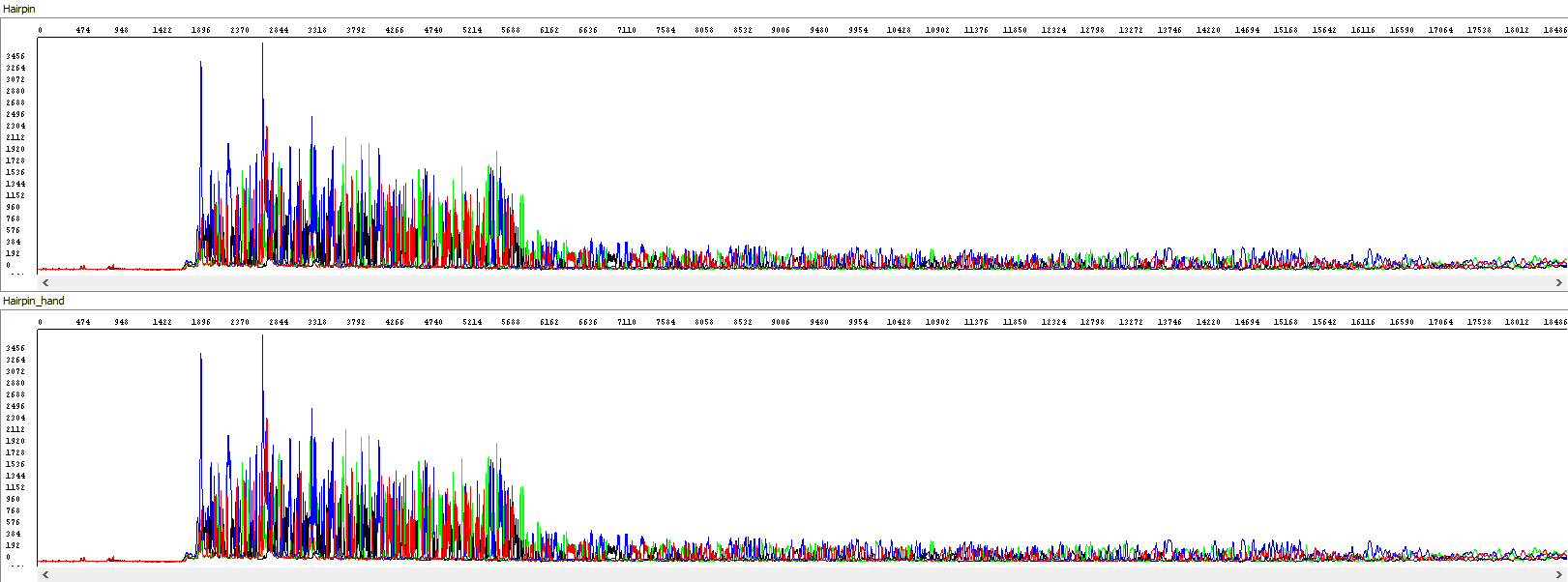
Příklad 1 - Optimalizace délky čtení, horní okno zobrazuje standardní analýzu automatickým algoritmem (délka čtení 934 bází, QV20), dolní okno týž vzorek po reanalýze algoritmem PeakTrace (délka čtení 1113 bází, QV20, o 19% delší sekvence):
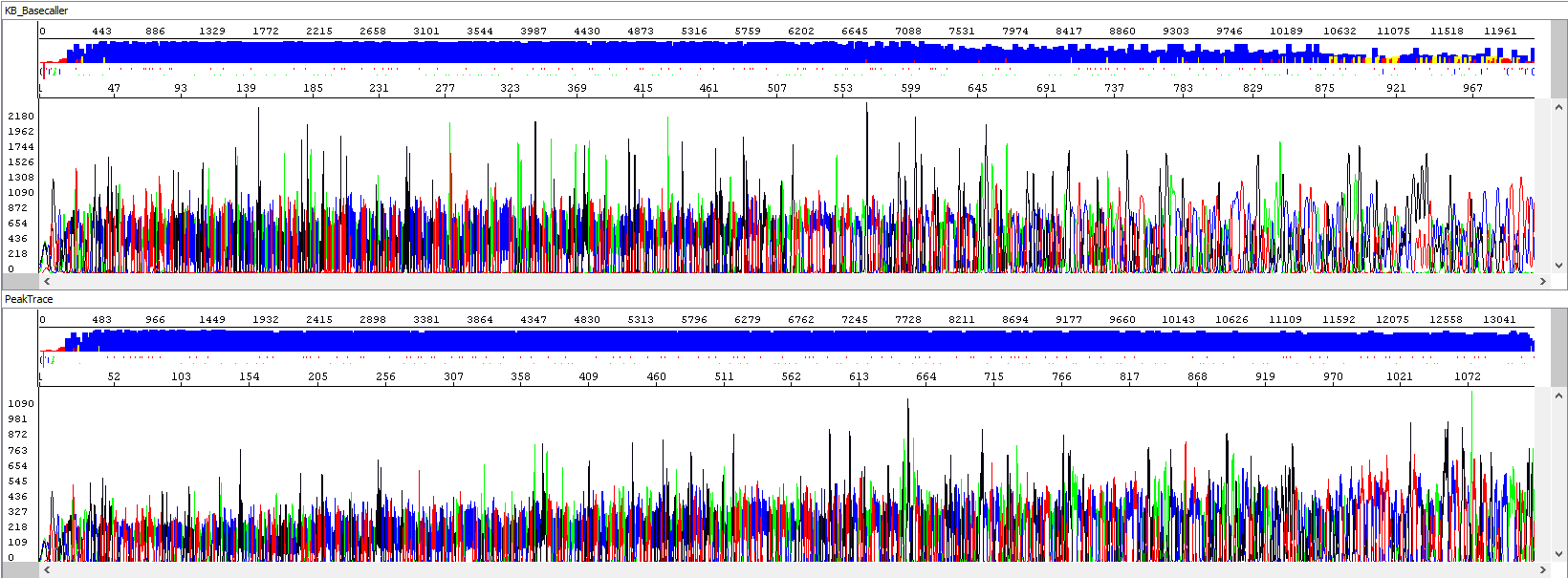
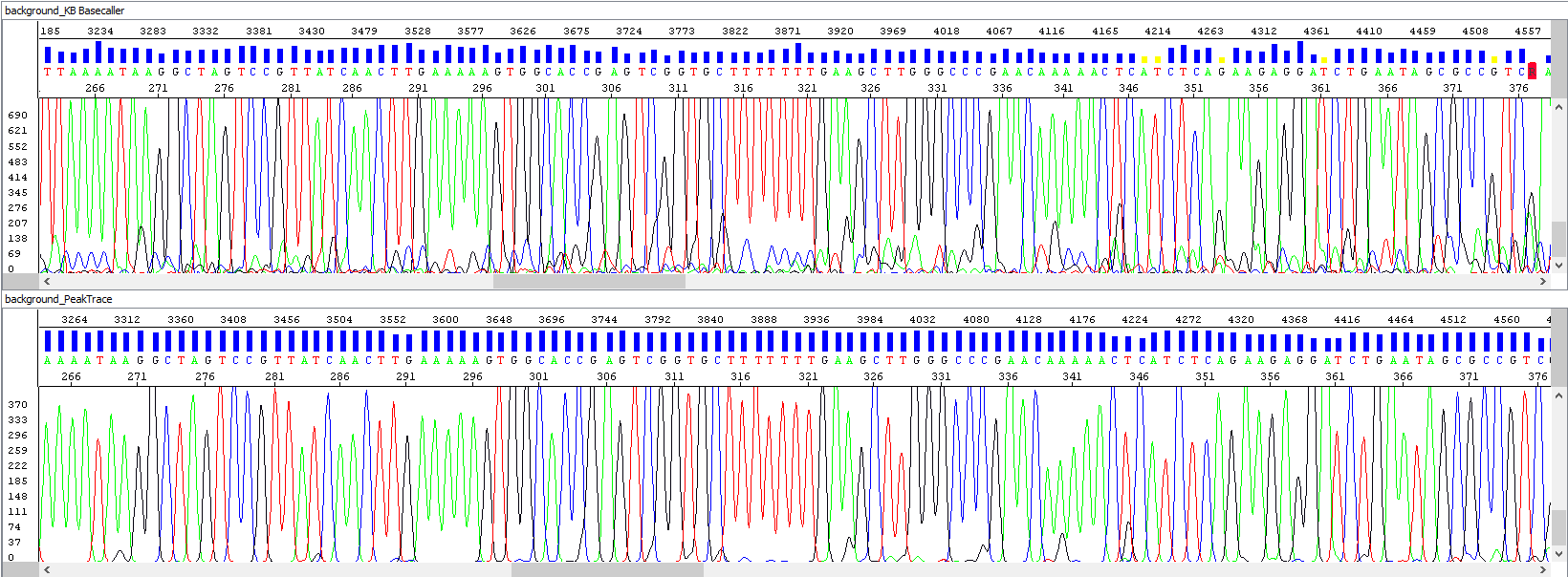
Příklad 2 - Optimalizace signálu pozadí, v horní části automatický algoritmus, spodní okno algoritmus PeakTrace, povšimněte si především pozadí sekvencí, obrázek hovoří sám za sebe:
• Krátká délka čtení – skutečný konec sekvence?
Některá sekvenační čtení jsou ukončena náhle a předčasně. Možným důvodem může být přítomnost sekundární struktury (vlásenky) či GC bohaté oblasti v analyzované sekvenci (více se této problematice věnujeme zde). Často sekvence v problematickém úseku skutečně končí (polymeráza dále nečte), ale také jsou případy, kdy v daném místě dojde k významnému poklesu intenzity fluorescenčního signálu, ale sekvence pokračuje (vlásenka byla alespoň částečně pročtena). Bez subjektivního prohlédnutí hrubých dat a manuální úpravy parametrů analýzy je obvyklým výsledkem automatické analýzy pouze krátká sekvence končící zmíněnou problematickou oblastí. Bylo by velikou škodou o pokračující data přijít, proto tyto sekvence vždy ručně přeanalyzujeme, abychom získali co možná nejdelší možné čtení.
Příklad 3 - Optimalizace délky čtení v případě přítomnosti vlásenky, horní okno zobrazuje standardní analýzu automatickým algoritmem (délka čtení 284 bází, QV20), dolní okno po manuálním zásahu operátora, který čtení jednak prodlouží a jednak současně využije reanalýzu algoritmem PeakTrace (délka čtení 1106 bází, QV20, o 389% delší sekvence):
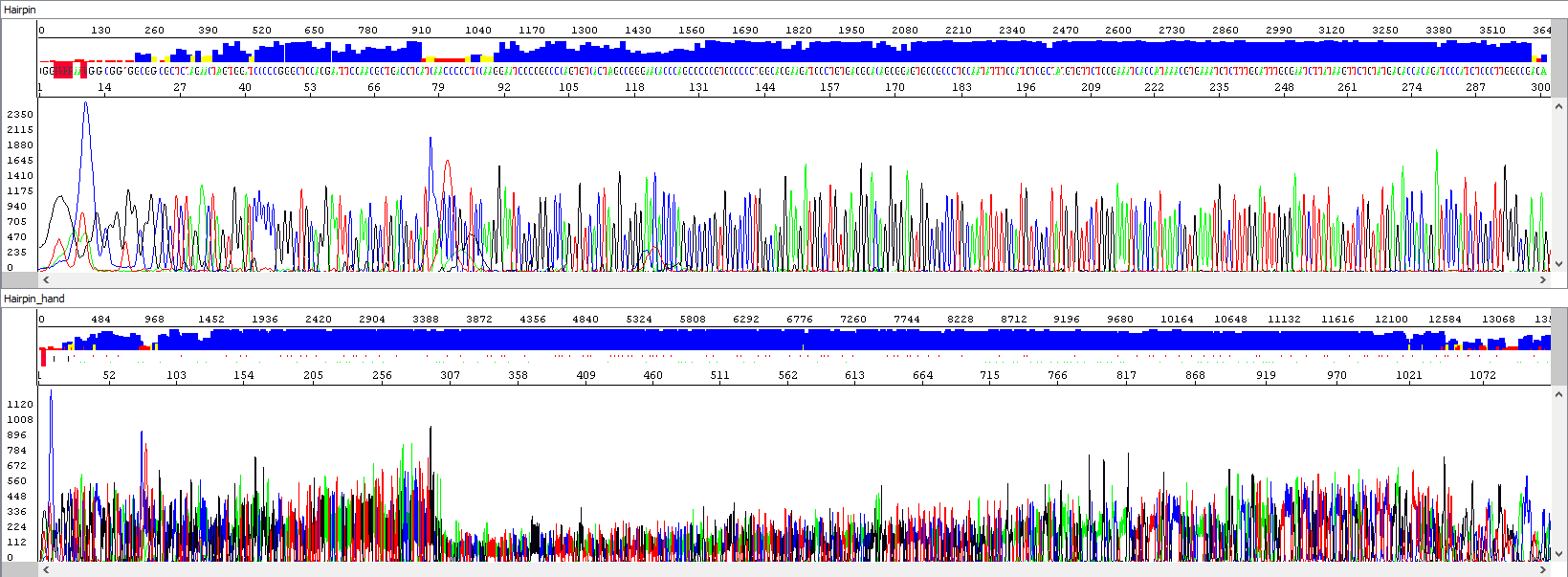
Pro doplnění náhled na hrubá data - identická v obou oknech:
Z náhledu je zřejmé, že operátor pouze dokonale využil sekvenci, kterou automatický algoritmus prostě využít neumí.
• Primerové dimery – nečitelný začátek
V některých případech se setkáváme s velmi krátkými nežádoucími fragmenty na začátku sekvence. Může se jednat o primerové dimery či jiné nespecifické produkty PCR či sekvenační reakce. Jelikož jsou zpravidla ve vzorku v přebytku, dochází na začátku sekvenační reakce k vyčerpání značených nukleotidů pro tvorbu těchto krátkých produktů a na žádoucí sekvenci jich již mnoho „nezbyde“. Výsledkem je sekvence s nečitelným začátkem o vysoké intenzitě signálu (kde se jednotlivé píky vzájemně překrývají) a zhoršená vizualizace a kvalita pokračující žádané sekvence. Taková data opět ručně upravujeme, především odstraněním směsných počátečních úseků.
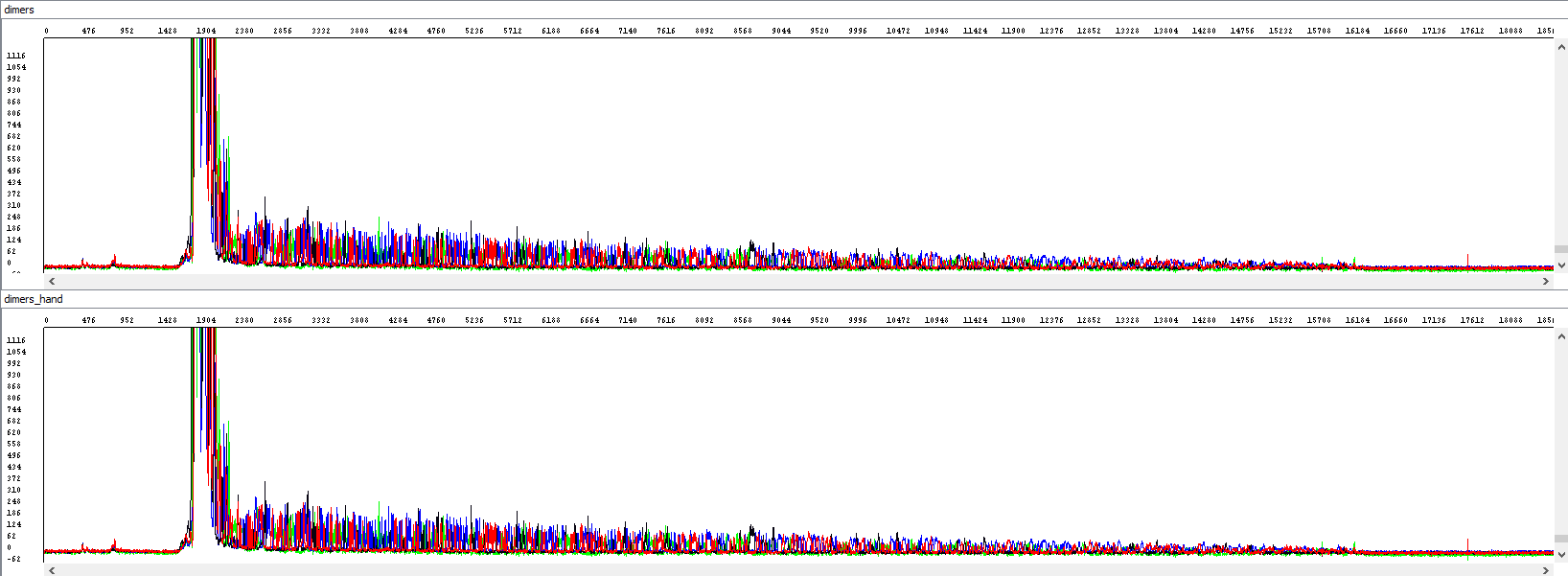
Příklad 4 - Optimalizace délky čtení v případě přítomnosti primerových dimerů, horní okno zobrazuje standardní analýzu automatickým algoritmem, která je naprosto nepoužitelná (délka čtení 0), dolní okno po reanalýze zkušeným operátorem (délka čtení 863 bází, QV20):

Pro doplnění opět náhled na hrubá data, zoomováno - je vidět obrovský primerový pík, identický v obou oknech a vlastní signál (poměrně slabý, ale aspoň něco, přečteme z něj uvedených 863 bází, ale jen když do procesu ručně zasáhneme):
• Pozdní migrace vzorku v kapiláře a šance na kvalitní sekvenci
U některých sekvencí začíná signál později, než očekáváme, a zároveň dochází k rychlé ztrátě rozlišení jednotlivých bází (pozorovatelné je to zejména v hrubých datech). Příčinou může být neoptimální nástřik vzorku do kapiláry (de facto technická chyba stroje řešitelná opakováním analýzy), ale nejčastěji jde o přítomnost nespecifických nečistot ve vzorku, které interferují s kapilární elektroforézou a způsobují onu opožděnou migraci. To se samozřejmě odráží na kvalitě dat, kdy jednotlivé báze v podstatě ani nemohou být spolehlivě rozlišeny (výsledek je podobný jako ztráta rozlišení demonstrovaná níže, příklad č. 5). Automatický basecaller toto přirozeně neví, ale my ano a i v těchto případech většinou získáváme perfektní sekvence po správném naředění vzorku a opakované elektroforéze. Fakticky to samozřejmě znamená pozdější dodání výsledku, protože analýza se prostě musí zopakovat.
• Sekvenační artefakty
Automatické sekvenátory jsou velmi přesné a citlivé, občas se však ve výsledných datech vyskytují jisté separační artefakty, které mohou negativně ovlivnit interpretaci analyzované sekvence (v extrémním případě může být artefakt posuzován jako nukleotidová variace v sekvenci DNA, mutace). Snažíme se tyto jevy minimalizovat – jednak samozřejmě nejlepší možnou péčí o naše sekvenátory a také tím, že vizuálně kontrolujeme každou sekvenci, která nám projde kapilárou. Pakliže na tento problém narazíme, automaticky analýzu co nejrychleji opakujeme.
Mezi nejběžnější artefakty patří například ztráta rozlišení uprostřed sekvence, či tzv. spiky (vícebarevné překrývající se píky), které se v sekvenci vyskytují náhodně. Nejčastěji jsou způsobeny malými vzduchovými bublinami, mikrokrystalky uvnitř polymeru v kapiláře nebo nedokonalou výměnou polymeru mezi jednotlivými běhy. Příčin může být samozřejmě více, nicméně určitě existuje také vazba mezi kvalitou templátu a tím, do jaké míry mohou případné separační artefakty výslednou sekvenci ovlivnit - ve vzorcích se slabým signálem (např. s nízkou koncentrací templátu) se tyto problémy projeví mnohem výrazněji.
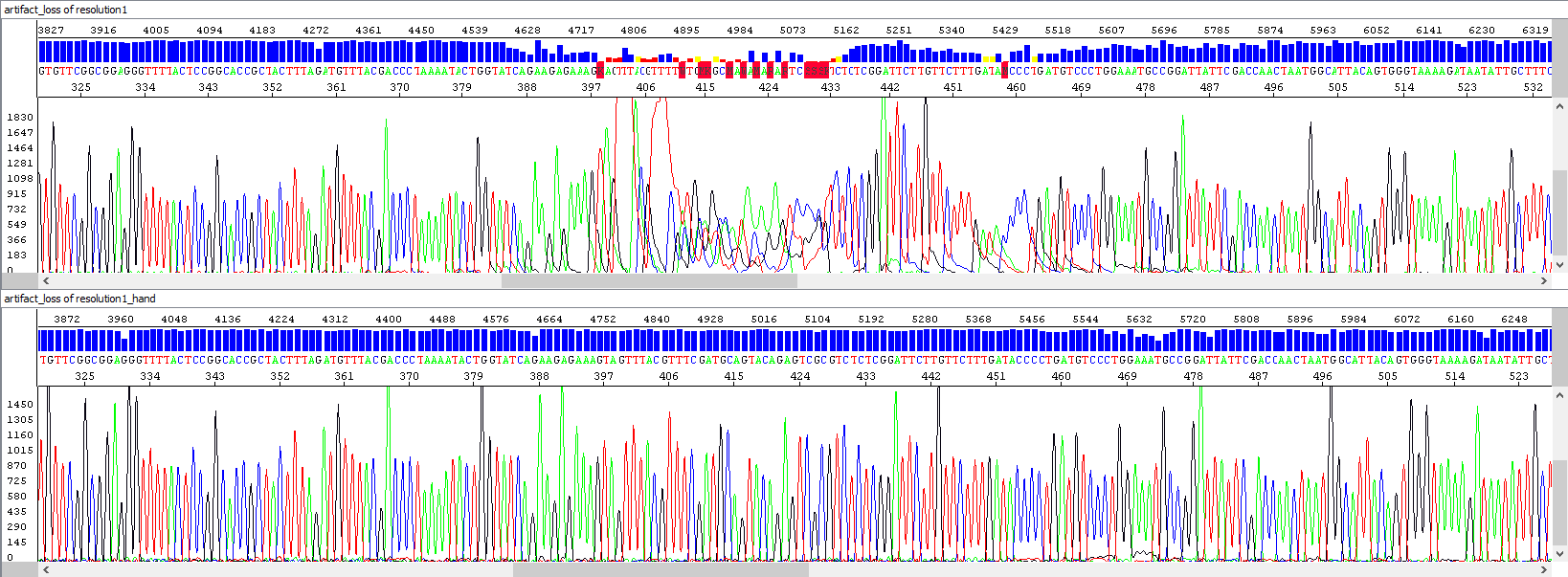
Příklad 5 - Opakovaná analýza (spodní okno) po ztrátě rozlišení (horní okno), zřejmě vlivem kontaminace:
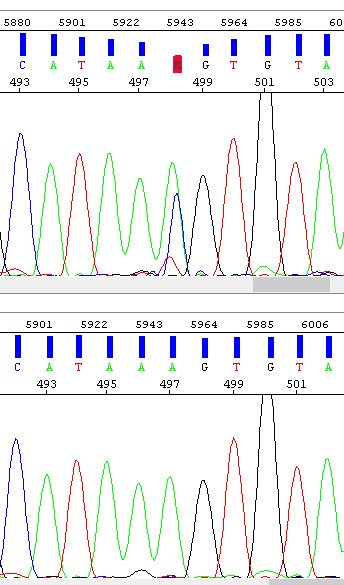
Příklad 6 - Tzv. Spike, jehož důsledkem je "mutace" v pozici 498. Operátor tento problém zaznamenal a analýzu opakoval (dolní okno) - výsledkem je čistá sekvence.
Neúspěšná sekvenační analýza – není nám to lhostejné
Bohužel, ne všechny sekvenační analýzy vycházejí optimálně anebo ještě hůře – nevycházejí vůbec. Ačkoliv nemůžeme znát pozadí všech sekvenačních analýz, které provádíme (ve smyslu cíle experimentu a oblasti zájmu), často na základě analyzovaných dat dokážeme rozpoznat, kde může být problém neúspěchu. Jelikož vaše data prohlížíme opravdu pečlivě, není neobvyklé, že naše postřehy dostanete jako komentář k vaší zakázce (nejčastěji se tyto problémy týkají koncentrací reakčních složek, směsných templátů, pravděpodobné přítomnosti inhibitorů sekvenační reakce, primerových dimerů, homopolymerů, repetitivních úseků, sekundárních struktur či GC bohatých oblastí templátu, apod.). Jsme rádi, že vám tímto poradenstvím můžeme pomoci k získání lepších výsledků.
V souhrnu lze říci, že všechny příklady uvedené výše budou pomocí automatických algoritmů někdy vyhodnoceny dobře a někdy ne. Zkušený operátor je vyhodnotí správně vždy. V SEQme se domníváme, že právě proto stojí za to, když se na vaše data naši zkušení operátoři podívají! Závěrem bychom rádi konstatovali, že problémy popsané výše řešíme velmi často automaticky aniž vás o nich informujeme, takže pokud máte pocit, že jste uvedená problematická data nikdy neviděli, je to právě proto :-)
Sanger lab, info@seqme.eu